
Under-display cameras using machine learning
In devices used for videoconferencing, locating the camera behind the display would improve the experience by putting the camera’s viewpoint nearer where the user is looking, thereby recreating the experience of eye contact that individuals have in face-to-face conversations. Additionally, it would allow the display to be larger, using the full surface of the device, and make for a cleaner design, uninterrupted by camera windows or notches.
However, capturing an image through the display entails addressing two objectives that are at odds with each other. First, the display must produce a bright, high-quality image. Secondly, enough light must pass through the display in the other direction for the camera to capture a clear image of the user. Unfortunately, improving the design for one of these goals tends to degrade the other. So, to side-step this conflict, this project investigates whether these challenges can be mitigated computationally.
In addition to this software-based approach, the team has also investigated using active sensing to improve through-screen image capture using optical hardware-based techniques.
The difficulty of capturing an image through the screen is readily apparent when we look at close-ups of typical display panels.
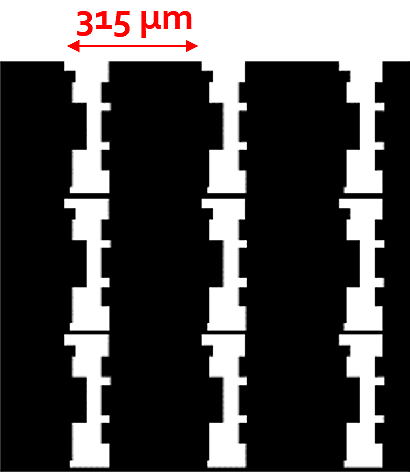

Making the problem even more challenging, these structures are small enough that they diffract the light passing through them, badly degrading the image and corrupting the spatial frequencies in unusual ways due to the complex shapes of the openings.
Below are images of the point spread functions (PSF) of the sample T‑OLED and P‑OLED displays mentioned above. A PSF describes what will happen to a point source of light passing through the system (in this case, the displays). A perfect imaging system would leave the point source looking like a point in the PSF. But here the single point of light is diffracted into many additional unintended points (called "side lobes") spread over the image. Since this happens for each source "point" in a real scene, this causes the image to blur as these side lobes mix in unrelated pixels across the sensor. In the PSFs shown, you can see how the differing structures of the two displays diffract the image differently.


The process
To correct for these distortions, we investigated using supervised learning to train a neural network to produce the unobstructed image given the degraded image. To get data for this training, we constructed an imaging system that photographs a scene (an image on a separate monitor) with a camera twice: once while looking through a display sample and again while unobstructed. A network was trained for each of the two displays described above. (For a more detailed description of the recovery process, see the linked publication.)
The results
The recovered images were found to be sharper and less noisy with both T‑OLED and P‑OLED displays.


Images captured through the P‑OLED display were almost indistinguishable, but the recovery produced a striking improvement:


Across the data set, the neural network achieved a 200% gain in contrast, with a 97% image restoration and a gain of 10 dB in SNR, showing potential for this approach.
Table 1. Modulation-transfer function (MTF) budget for camera placed under T‑OLED and under P‑OLED
| Attribute | T‑OLED | P‑OLED |
|---|---|---|
| Fraction | Fraction | |
| Contrast | 0.3 | 0.17 |
| NN gain | 3 | 5.29 |
| Total Loss | 0.9 | 0.9 |
Table 2. SNR budget for camera placed under T‑OLED and under P‑OLED
| Attribute | T‑OLED | P‑OLED | ||
|---|---|---|---|---|
| Fraction | dB | Fraction | dB | |
| Transmission | 0.2 | -7.0 | 0.03 | -15.2 |
| NN gain | 1.58 | 2.0 | 10 | 10.0 |
| Total Loss | 0.32 | -5.0 | 0.3 | -5.2 |
Related projects
- Under-Display Camera Using Active Sensing
- Camera in Display: Machine Learning and Embedded Cameras Make Possible a New Class of More Natural Videoconferencing Devices




