
Camera in display
Machine learning and embedded cameras make possible a new class of more natural videoconferencing devices
The idea of embedding cameras in a display is not new. From the earliest days of videoconferencing it was recognized that the separation of the camera and the display meant the system could not convey gaze awareness accurately. Videoconferencing systems remain unable to recreate eye contact—a key element of effective communication.
A second challenge has emerged more recently. The desire to maximize screen size on small devices such as cell phones leaves little room outside the display to locate a camera.
Placing cameras behind the screen could solve these problems, but doing so tends to degrade the image. Diffraction from the screen’s pixel structure can blur the image, reduce contrast, reduce usable light levels, and even obstruct some image content entirely, in ways that are dependent on the device’s display-pixel design.
Furthermore, there are other ways in which videoconferencing is oblivious to spatial factors, distorting the perceived size and position of participants as compared with a conversation in real space.
In this project we investigate how machine learning can help overcome some of the image degradation problems associated with placing cameras behind the display, and can help frame remote conversations in a more natural spatial environment.
The Perspective Problem
Locating the camera above the display results in a vantage point that’s different from a face-to-face conversation, especially with large displays, which can create a sense of looking down on the person speaking.
Worse, the distance between the camera and the display mean that the participants will not experience a sense of eye contact. If I look directly into your eyes on the screen, you will see me apparently gazing below your face. Conversely, if I look directly into the camera to give you a sense that I am looking into your eyes, I’m no longer in fact able to see your eyes, and I may miss subtle non-verbal feedback cues.
Taken together, the result can look more like surveillance video than a conversation!


These incongruities cause videoconferencing to fall short of its potential to create a sense of presence and faithfully reproduce the richness of face-to-face conversation.
Relocating the camera to the point on the screen where the remote participant’s face appears would achieve a natural perspective and a sense of eye contact.
The Diffraction Difficulty
With transparent OLED displays (T-OLED), we can position a camera behind the screen, potentially solving the perspective problem. But because the screen is not fully transparent, looking through it degrades image quality by introducing diffraction and noise.
Here we can see the effect of photographing a simple image through a T-OLED screen:


Pixel structure affects diffraction. In this example, the screen has a long, thin rectangle to view through:
Not surprisingly, this causes significant degradation, but only in the horizontal direction. We can visualize this effect by plotting the modulation-transfer function (MTF):
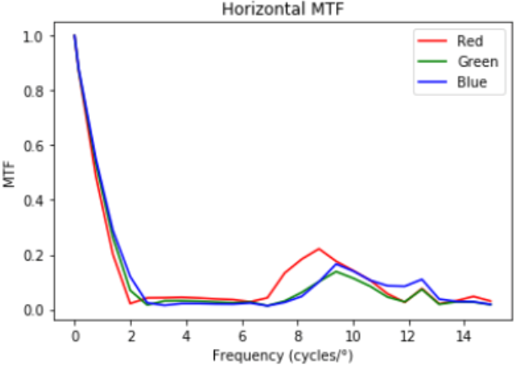
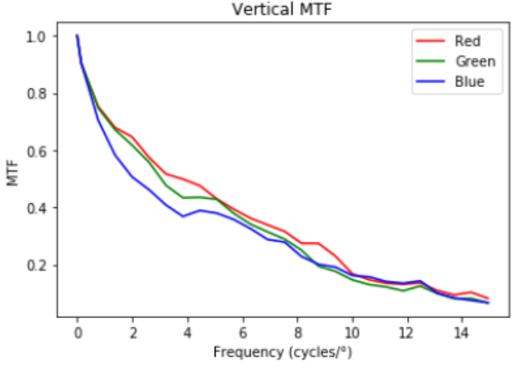
Image Recovery with U-Net
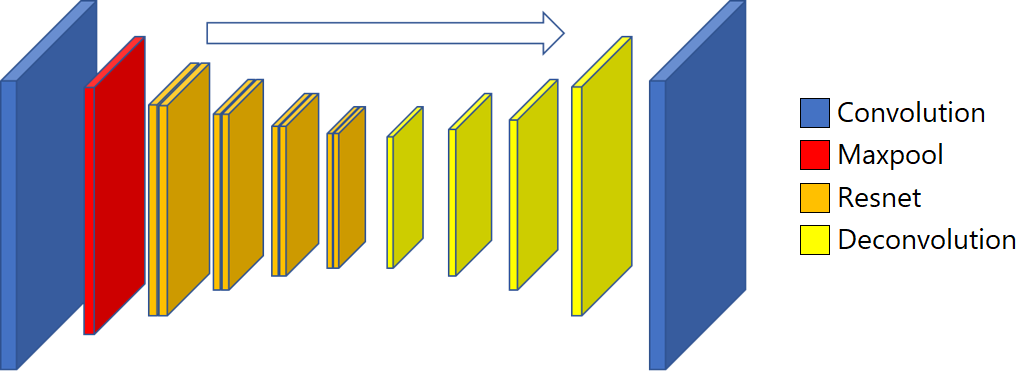
To compensate for the image degradation inherent in photographing through a T-OLED screen, we used a U-Net neural-network structure that both improves the signal-to-noise ratio and de-blurs the image.
We were able to achieve a recovered image that is virtually indistinguishable from an image that was photographed directly.









The ability to position cameras in the display and still maintain good image quality provides an effective solution to the perennial problems of gaze awareness and perspective.
Framing the Conversation

intimate, personal, social, and public
Spatial factors also affect conversational dynamics, but are not taken into account by current videoconferencing systems.
Both the arrangement of participants relative to each other and the distance between them (proxemics) are meaningful aspects of non-verbal communication.
Such factors could be applied to the virtual environment of a remote conversation by adjusting the speaker’s position and size on the display.
Image Segmentation
We devised a convolutional neural network (CNN) structure to find the speaker within the image.
First, we performed semantic segmentation to recognize and locate human forms within the image.


Next, we performed depth segmentation to find the nearest individual, whom we pick out as the current speaker. (This simple technique works well when there is a single main speaker, but more sophisticated techniques could be applied that take multiple factors into account in order to handle more complex multi-speaker scenarios.)
Correcting Scale
Having identified the speaker in the remote view, we can scale the incoming video so that the remote participant appears in a lifelike size on the local display.


One way to accomplish this would be to zoom the whole image and re-center it on the speaker. However, for this project we went a step further. We extracted and scaled the individual independently of the background, as seen in this video:
Isolating the people from the background opens up additional options. You can screen out a background that is distracting or that contains sensitive information. You can also use the background region to display other information, such as presentation slides or video that the speaker is talking about.
Conclusion
Human interaction in videoconferences can be made more natural by correcting gaze, scale, and position by using convolutional neural network segmentation together with cameras embedded in a partially transparent display. The diffraction and noise resulting from placing the camera behind the screen can be effectively removed using U-net neural network. Segmentation of live video also makes it possible to combine the speaker with a choice of background content.
Neural networks combined with T-OLED displays create a new class of videoconference devices.





