
Compression Driven Frame Interpolation
Video frame interpolation refers to the task of generating intermediate (non-existent) frames between actual frames in a sequence, which can largely increase the temporal resolution. DNN-based frame interpolation typically relies on heavy model architectures with a huge number of features, preventing them from being deployed on systems with limited resources, e.g., mobile devices.
In this project, we propose a compression-driven network design for frame interpolation (CDFI), that leverages model pruning through sparsity-inducing optimization to significantly reduce the model size while achieving superior performance. Concretely, we first compress the recently proposed AdaCoF model and show that a 10× compressed AdaCoF performs similarly as its original counterpart; then we further improve this compressed model by introducing a multi-resolution warping module, which boosts visual consistencies with multi-level details. Consequently, we achieve a significant performance gain with only a quarter in size compared with the original AdaCoF. Moreover, our model performs favorably against other state-of-the-arts in a broad range of datasets. Finally, the proposed compression-driven framework is generic and can be easily transferred to other DNN-based frame interpolation algorithms.
The pipeline of CDFI
We present CDFI as a two-stage approach which first uses model compression (via fine-grained pruning based on sparsity-inducing optimization) as a guide in determining an efficient architecture and then improves upon it. The pipeline is illustrated in the following figure.
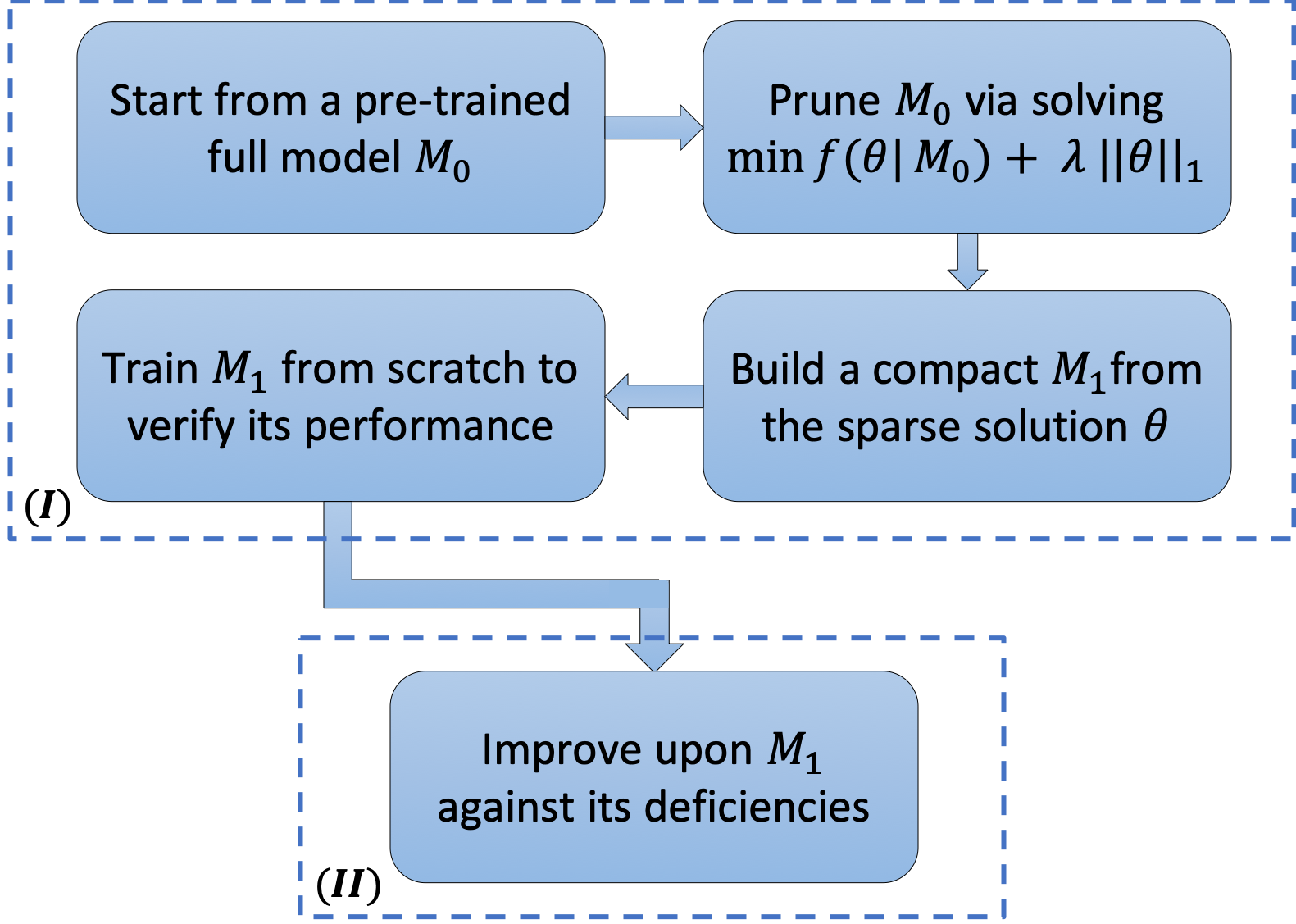
CDFI applied to AdaCoF model
As an example, we compress the recently proposed AdaCoF and show that a 10x compressed AdaCoF is still able to maintain a similar benchmark performance as before, indicating a considerable amount of redundancy in the original model.
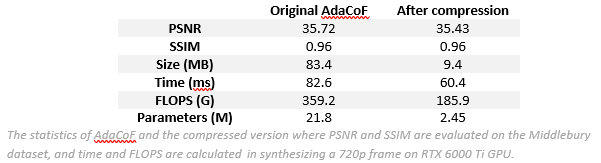
The compression provides us two direct benefits: (i) it helps us understand the model architecture in depth, which in turn inspires an efficient design; (ii) the obtained compact model makes more room for further improvements that could potentially boost the performance to a new level.
By observing that AdaCoF is capable of handling large motion while is short of dealing with occlusion or preserving finer details, we improve upon the compact model by introducing a multi-resolution warping module that utilizes a feature pyramid representation of the input frames to help with the image synthesis. As a result, our final model outperforms AdaCoF on three benchmark datasets with a large margin (more than 1 dB of PSNR on the Middlebury dataset) while it is only a quarter of its initial size. Note that typically it is difficult to implement the same improvements on the original heavy model. Experiments show that our model also performs favorably against other state-of-the-art methods.
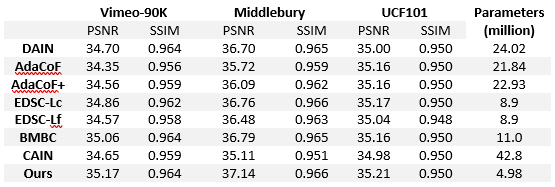
The following figures show qualitative comparisons of these methods, with left to right: ground-truth image, overlaid patch, AdaCoF+, BMBC, CAIN, EDSC-Lc, EDSC-Lf, and ours. We remark that although our method is built upon compact AdaCoF, our predictions are much sharper and more realistic than the baseline model. Moreover, our results are more appealing compared with the other state-of-the-arts in handling large motion, occlusion, and fine details.


Further Applications
In addition to the generation of slowmotion videos as demonstrated, the outcome of this project have other interesting applications. Imagine a scenario where we have two cameras side-by-side taking pictures at the same time, one may use our frame interpolation algorithm to synthesize the in-between picture as if there is a virtual middle camera. Note that this spatial-domain problem is not intended to increase the temporal resolution since the two input pictures are captured at the same time. However, by treating it as a video frame interpolation task in the temporal domain, it leads to promising results, and suggests its broad application prospects.



